Chỉ thị biên dịch là phần mở rộng của ngôn ngữ lập trình. Việc thêm các chỉ thị vào chương trình tuần tự cho phép thực thi song song.
Một chỉ thị biên dịch bao gồm các thành phần sau:
- Định danh chỉ thị (
#pragma omp) - Tên chỉ thị (parallel, for, section, v.v.)
- Các mệnh đề (private, shared, reduction, copyin, v.v.)
Chỉ thị vùng song song
Vùng song song là một đoạn mã có thể được thực thi đồng thời bởi nhiều luồng. Cuối vùng song song có một điểm đồng bộ ẩn (barrier).
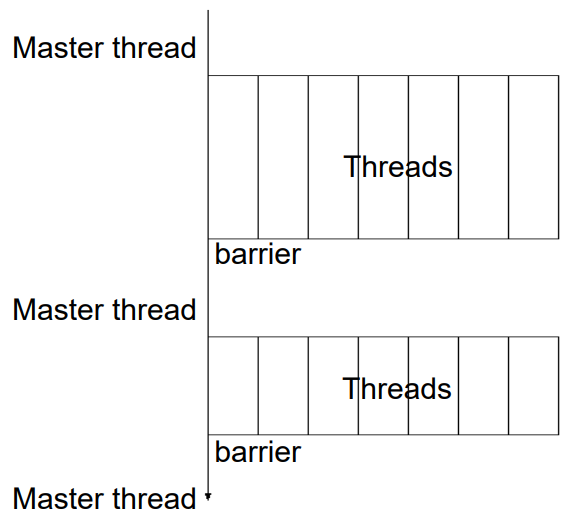
Chỉ thị vòng lặp for
#include <iostream>
#include <omp.h>
using namespace std;
int main(int argc, char* argv[]){
int maxThreads = omp_get_max_threads();
int numProcs = omp_get_num_procs();
cout << "Số luồng tối đa: " << maxThreads << " Số bộ xử lý: " << numProcs << endl;
#pragma omp parallel for
for (int i = 0; i < 10; ++i) {
int currentNumThreads = omp_get_num_threads();
int threadId = omp_get_thread_num();
cout << "Luồng " << threadId << " --> " << i << endl;
}
return 0;
}Lưu ý: Chỉ thị #pragma omp parallel for không tạo số luồng dựa trên số lần lặp của vòng lặp. Thay vào đó, OpenMP quyết định số luồng dựa trên cấu hình hệ thống hiện tại (ví dụ: số lõi CPU). Do đó, một luồng có thể xử lý nhiều lần lặp, và mối quan hệ giữa luồng và lần lặp không nhất thiết là một-một.
Để chỉ định số tiến trình (process) cho node, sử dụng lệnh salloc -p com -N 1 -n 32, nếu không mặc định là 1, và giá trị n phải nhỏ hơn hoặc bằng số lõi CPU của node. ---> omp_get_max_threads() ---> 32
Mệnh đề lập lịch schedule
Mệnh đề schedule xác định cách phân bổ các lần lặp của vòng lặp song song cho các luồng khác nhau. Nó cho phép bạn kiểm soát chiến lược phân bổ để tối ưu hiệu năng hoặc đáp ứng các yêu cầu cụ thể. Mệnh đề này chỉ định kích thước khối (chunk size) cho việc chia vòng lặp và phạm vi khối mà mỗi luồng thực thi.
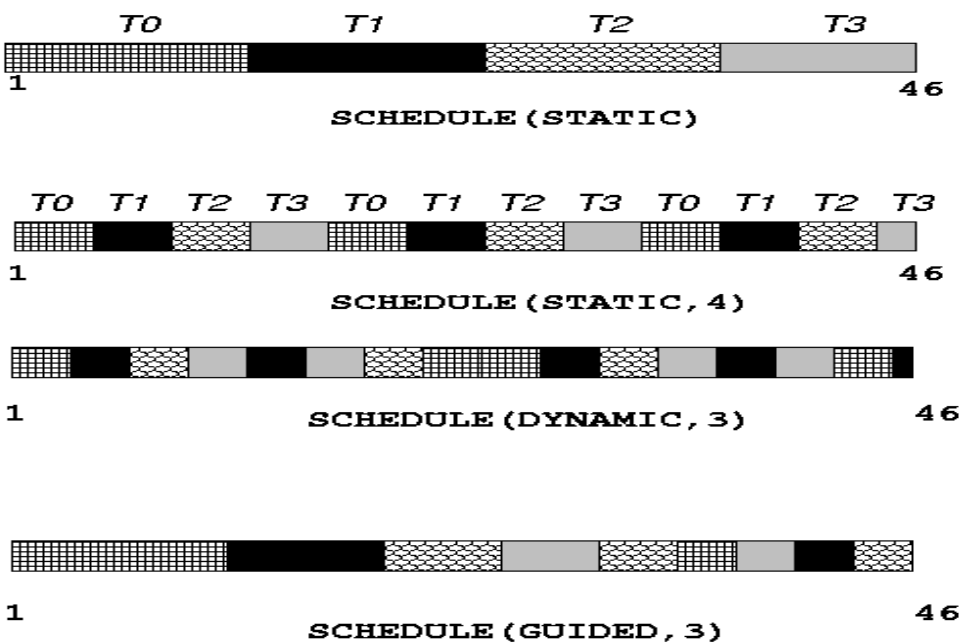
static
schedule (static, chunksize): Nếu bỏ qua chunksize, không gian lặp được chia thành các vùng có kích thước xấp xỉ bằng nhau, mỗi luồng nhận một vùng. Nếu chỉ định chunksize, không gian lặp được chia thành các khối có kích thước là chunksize, sau đó được phân phối theo vòng tròn cho các luồng.
#include <iostream>
#include <omp.h>
using namespace std;
int main(int argc, char* argv[]){
int arr[12], threadId, k;
#pragma omp parallel for private(threadId) num_threads(4) schedule(static)
for (int i = 0; i < 12; ++i) {
threadId = omp_get_thread_num();
arr[i] = threadId;
}
for (int i = 0; i < 12; ++i) {
cout << "Luồng " << arr[i] << " --> " << i << endl;
}
return 0;
}schedule(static)
Luồng 0 --> 0
Luồng 0 --> 1
Luồng 0 --> 2
Luồng 1 --> 3
Luồng 1 --> 4
Luồng 1 --> 5
Luồng 2 --> 6
Luồng 2 --> 7
Luồng 2 --> 8
Luồng 3 --> 9
Luồng 3 --> 10
Luồng 3 --> 11schedule(static, 2)
Luồng 0 --> 0
Luồng 0 --> 1
Luồng 1 --> 2
Luồng 1 --> 3
Luồng 2 --> 4
Luồng 2 --> 5
Luồng 3 --> 6
Luồng 3 --> 7
Luồng 0 --> 8
Luồng 0 --> 9
Luồng 1 --> 10
Luồng 1 --> 11dynamic
schedule (dynamic, chunksize): Chia không gian lặp thành các khối có kích thước chunksize, sau đó phân phối cho các luồng theo cơ chế đến trước phục vụ trước (FCFS). Nếu bỏ qua chunksize, giá trị mặc định là 1.
schedule(dynamic, 2)
Luồng 0 --> 0
Luồng 0 --> 1
Luồng 1 --> 2
Luồng 1 --> 3
Luồng 1 --> 4
Luồng 1 --> 5
Luồng 1 --> 6
Luồng 1 --> 7
Luồng 1 --> 8
Luồng 1 --> 9
Luồng 3 --> 10
Luồng 3 --> 11schedule(dynamic)
Luồng 0 --> 0
Luồng 0 --> 1
Luồng 0 --> 2
Luồng 2 --> 3
Luồng 0 --> 4
Luồng 2 --> 5
Luồng 2 --> 6
Luồng 2 --> 7
Luồng 2 --> 8
Luồng 3 --> 9
Luồng 2 --> 10
Luồng 2 --> 11guided
schedule (guided, chunksize): Phân phối động các khối lặp cho các luồng, nhưng kích thước khối giảm dần khi vòng lặp tiến triển. Phương pháp này hiệu quả khi các lần lặp đầu tiên tốn nhiều thời gian hơn các lần sau. chunksize chỉ định kích thước khối tối thiểu, mặc định là 1.
runtime
schedule (runtime): Quyết định chiến lược lập lịch cho vòng lặp song song tại thời điểm chạy. Khi sử dụng schedule(runtime), OpenMP sẽ chọn chiến lược phù hợp nhất (static, dynamic, hoặc guided) dựa trên môi trường hệ thống và tài nguyên khả dụng tại thời điểm thực thi. Việc này cho phép tự động thích ứng với các điều kiện khác nhau để đạt hiệu năng tối ưu.
#pragma omp parallel for schedule(runtime)